
Seung-MinJi
[알고리즘] 퀵정렬 본문
1. 퀵 정렬 (quick sort)이란?
- 정렬 알고리즘의 꽃
- 기준점(PIVOT)을 정해서 기준점보다 작은 데이터는 왼쪽, 큰 데이터는 오른쪽으로 모으는 함수를 작성함
- 각 왼쪽, 오른쪽은 재귀용법을 사용해서 다시 동일 함수를 호출하여 위 작업을 반복함
- 함수는 왼쪽 + 기준점 + 오른쪽을 리턴함
2. 알고리즘 구현
Quicksort 함수 만들기
- 만약 리스트 갯수가 한개이면 해당 리스트 리턴
- 그렇지 않다면, 리스트 맨 앞의 데이터를 기준점으로 놓기
- left,right 리스트 변수를 만들고
- 맨 앞의 데이터를 뺀 나머지 데이터를 기준점과 비교(pivot)
- 기준점보다 작으면 left.append(해당데이터)
- 기준점보다 작으면 left.append(해당데이터)
- return quicksort(left)+ pivot + quicksort(right)로 재귀 호출
import random
def qsort(data):
if len(data) <= 1:
return data
left, right = list(), list()
pivot = data[0]
for index in range(1, len(data)):
if pivot > data[index]:
left.append(data[index])
else:
right.append(data[index])
return qsort(left) + [pivot] + qsort(right)
data_list = random.sample(range(100), 10)
qsort(data_list)파이썬 comprehension을 이용해서 깔끔하게 작성
def qsort(data):
if len(data) <= 1:
return data
pivot = data[0]
left = [item for item in data[1:] if pivot > item]
right = [item for item in data[1:] if pivot <= item]
return qsort(left) + [pivot] + qsort(right)
import random
data_list = random.sample(range(100),10)
qsort(data_list)
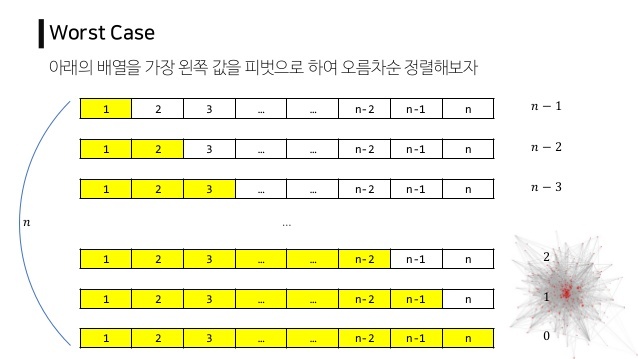
3. 알고리즘 분석
- 병합정렬과 유사, 시간복잡도는 O(n logn)
- 단, 최악의 경우
- 맨 처음 pivot이 가장 크거나, 가장 작으면
- 모든 데이터를 비교하는 상황이 나옴
- O(n^2)
'Computer Science' 카테고리의 다른 글
| [알고리즘] 이진 탐색 (0) | 2023.09.14 |
|---|---|
| [알고리즘] 병합정렬 (0) | 2023.09.12 |
| [알고리즘] 동적 계획법과 분할 정복 (0) | 2023.09.12 |
| [알고리즘] 재귀 용법 (1) | 2023.09.08 |
| [알고리즘] 공간 복잡도 (0) | 2023.09.08 |
'Computer Science' Related Articles
more



